综述
本篇以upload任务的sumbit 和 create 阶段为例,结合产生的日志,说明该生命阶段代码的运行情况。
执行步骤
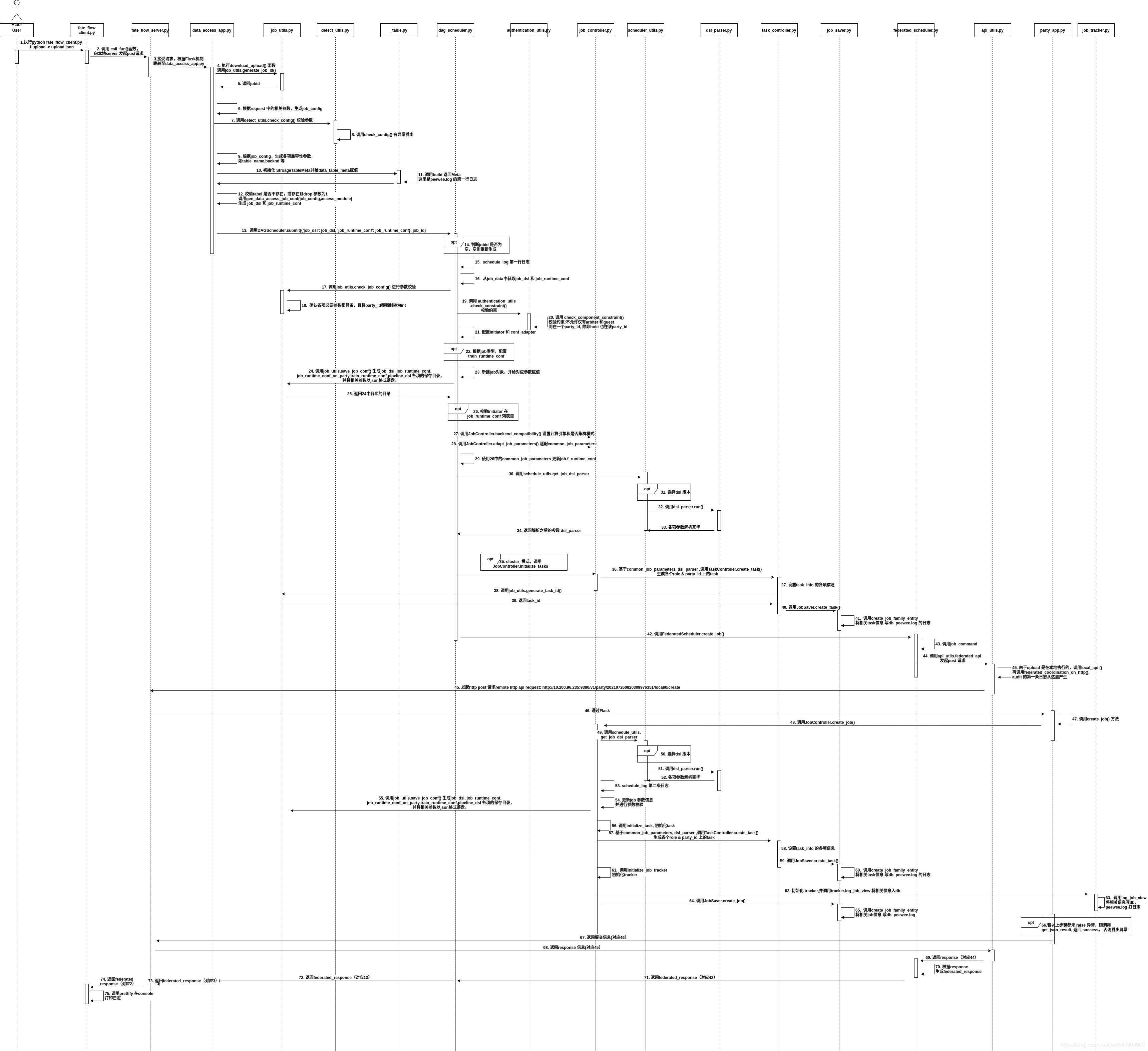
为便于说明,画了下uml 时序图,结合图说下各步操作
- 在CLI 用户执行命令 python fate_flow_client.py -f upload -c upload_guest.json
fate_flow_client.py:调用 call_fun()函数,向本地server 发起post请求
1
response = requests.post("/".join([server_url, "data", func.replace('_', '/')]), data=data,params=json.dumps(config_data),headers={'Content-Type': data.content_type})
这里会在容器日志中体现post请求日志
1
10.200.96.235 - - [26/Jul/2021 08:20:31] "POST /v1/data/upload?%7B%22file%22:%20%22/data/projects/fate/examples/data/breast_hetero_guest.csv%22,%20%22head%22:%201,%20%22partition%22:%201,%20%22work_mode%22:%201,%20%22table_name%22:%20%22hetero_guest%22,%20%22namespace%22:%20%22cl%22,%20%22config%22:%20%22/data/projects/fate/cl/upload_guest.json%22,%20%22function%22:%20%22upload%22%7D HTTP/1.1" 200 -
fate_flow_server.py: 接受请求,Flask的调度,跳转至data_access_app.py
- data_access_app.py: 执行download_upload() 函数,判断job_id 是否为空,若为空则调用job_utils.generate_job_id()
- job_utils.py: 执行generate_job_id() 并返回ID
- data_access_app.py: 根据request 中的相关参数,生成job_config
- data_access_app.py: 调用detect_utils.check_config() 校验参数
- detect_utils.py: 执行check_config() 如有异常抛出
- data_access_app.py: 根据job_config,生成各项兼容性参数,如table_name,backnd 等
- data_access_app.py: 初始化 StroageTableMeta并给data_table_meta赋值
- table.py: 调用build 返回Meta,这里打出fateflow/peewee.log 的第3行日志
这里在初始化 StorageTableMeta 的时候,会调用__new() -> query_table_meta() 从而在peewee 留下日志。1
[DEBUG] [2021-07-26 08:20:31,008] [1:140259119585024] - peewee.py[line:2863]: ('SELECT `t1`.`f_create_date`, `t1`.`f_update_date`, `t1`.`f_name`, `t1`.`f_namespace`, `t1`.`f_address`, `t1`.`f_engine`, `t1`.`f_type`, `t1`.`f_options`, `t1`.`f_partitions`, `t1`.`f_id_delimiter`, `t1`.`f_in_serialized`, `t1`.`f_have_head`, `t1`.`f_schema`, `t1`.`f_count`, `t1`.`f_part_of_data`, `t1`.`f_description`, `t1`.`f_create_time`, `t1`.`f_update_time` FROM `t_storage_table_meta` AS `t1` WHERE ((`t1`.`f_name` = %s) AND (`t1`.`f_namespace` = %s))', ['hetero_guest', 'cl'])
- data_access_app.py: 校验tabel 不存在,或存在且drop 参数为1,调用gen_data_access_job_conf(job_config,access_module) 生成 job_dsl 和 job_runtime_conf
- data_access_app.py: 调用DAGScheduler.submit({‘job_dsl’: job_dsl, job_runtime_conf’: job_runtime_conf}, job_id) 提交任务
- dag_scheduler.py: 判断jobid 是否为空,空则重新生成
dag_scheduler.py: 打印出${job_log_dir}/fate_flow_schedule.log的第一行日志
1
[INFO] [2021-07-26 08:20:31,014] [1:140259119585024] - dag_scheduler.py[line:40]: submit job, job_id 202107260820309976351, body {'job_dsl': {'components': {'upload_0': {'module': 'Upload'}}}, 'job_runtime_conf': {'initiator': {'role': 'local', 'party_id': 0}, 'job_parameters': {'common': {'backend': 0, 'work_mode': 1}}, 'role': {'local': [0]}, 'component_parameters': {'role': {'local': {'0': {'upload_0': {'name': 'hetero_guest', 'head': 1, 'file': '/data/projects/fate/jobs/202107260820309976351/fate_upload_tmp/breast_hetero_guest.csv', 'partition': 1, 'namespace': 'cl', 'destroy': False}}}}}, 'dsl_version': 2}}
其中json部分是入参job_data,可以看到,整个body,包含两部分job_dsl 和 job_runtime_conf。job_dsl 定义了所使用的components,这里只有一个upload。
job_runtime_conf定义了整个job的相关参数,包括:- initiator: 调度者(或联邦任务的发起者)
- job_parameters:job参数,主要是work_mode:是否为集群模式和 backend 计算引擎
- role: 本次任务的参与角色
- component_parameters: 位于各个role上的component 的参数,这里就是upload_0 的各项参数
dag_scheduler.py: 从job_data中获取job_dsl 和 job_runtime_conf
- dag_scheduler.py: 调用job_utils.check_job_config() 进行参数校验
- job_utils.py: 确认各项必要参数都具备,且将party_id都强制转为int。如有异常,则raise。
- dag_scheduler.py: 调用 authentication_utils.check_constraint() 校验约束
- authentication_utils.py: 调用 check_component_constraint(),校验约束:不允许仅有arbiter 和guest,同在一个party_id, 除非host 也在该party_id
- dag_scheduler.py: 配置initiator 和 conf_adapter
- dag_scheduler.py: 根据job类型,配置train_runtime_conf
- dag_scheduler.py: 新建job对象,并给对应参数赋值
- dag_scheduler.py: 调用job_utils.save_job_conf() 生成job_dsl, job_runtime_conf,job_runtime_conf_on_party,train_runtime_conf,pipeline_dsl 各项的保存目录,并将相关参数以json格式落盘。
- job_utils.py: 返回24中各项的目录
- dag_scheduler.py: 校验initiator 在job_runtime_conf 列表里
- dag_scheduler.py: 调用JobController.backend_compatibility() 设置计算引擎和是否集群模式
- dag_scheduler.py: 调用JobController.adapt_job_parameters() 适配common_job_parameters
- dag_scheduler.py: 使用28中的common_job_parameters 更新job.f_runtime_conf(job 为23 新建对象)
- dag_scheduler.py: 调用schedule_utils.get_job_dsl_parser 解析参数
- scheduler_utils.py: 根据配置选择dsl 版本(v1 或v2)
- scheduler_utils.py: 调用dsl_parser.run() 解析参数
- dsl_parser.py: 解析完毕
- scheduler_utils.py: 返回dsl_parser 对象
- dag_scheduler.py: 若为cluster 模式,且role 和 partyid 不为initiator(if role == job.f_initiator_role and party_id == job.f_initiator_party_id: continue),调用 JobController.initialize_tasks,故而后面36-41都不会执行
- job_controller.py: 基于common_job_parameters, dsl_parser ,调用TaskController.create_task(),生成除initiator 外各个role & party_id 上的task
- task_controller.py: 设置task_info 的各项信息
- task_controller.py: 调用job_utils.generate_task_id()
- job_utils.py: 返回task_id
- task_controller.py: 调用JobSaver.create_task()
- job_saver.py: 调用create_job_family_entity将相关task信息入DB
- dag_scheduler.py: 调用FederatedScheduler.create_job()
- federated_scheduler.py: 调用job_command()
- federated_scheduler.py: 调用api_utils.federated_api() 发起post请求。
- api_utils.py: 由于upload 是在本地执行的,调用依次调用local_api()->federated_coordination_on_http(),${job_log_dir}/fate_flow_audit.log 的第一条日志从这里产生
1
[INFO] [2021-07-26 08:20:31,028] [1:140259119585024] - api_utils.py[line:122]: remote http api request: http://10.200.96.235:9380/v1/party/202107260820309976351/local/0/create
- fate_flow_server.py: sever 端接受到如上请求,通过Flask,跳转至party_app.py
- party_app.py: 调用create_job()
- party_app.py: 调用JobController.create_job()
- job_controller.py: 调用schedule_utils.get_job_dsl_parser 解析参数
- scheduler_utils.py: 根据配置选择dsl 版本(v1 或v2)
- scheduler_utils.py: 调用dsl_parser.run() 解析参数
- dsl_parser.py: 解析完毕
- job_controller.py: 打印出${job_log_dir}/fate_flow_schedule.log的第二行日志
schedule_logger(job_id).info(‘job parameters:{}’.format(job_parameters))1
[INFO] [2021-07-26 08:20:31,043] [1:140259111192320] - job_controller.py[line:51]: job parameters:{'job_type': 'train', 'work_mode': 1, 'backend': 0, 'computing_engine': 'EGGROLL', 'federation_engine': 'EGGROLL', 'storage_engine': 'EGGROLL', 'engines_address': {}, 'federated_mode': 'MULTIPLE', 'task_parallelism': 1, 'computing_partitions': 4, 'federated_status_collect_type': 'PULL', 'model_id': 'local-0#model', 'model_version': '202107260820309976351', 'eggroll_run': {}, 'spark_run': {}, 'rabbitmq_run': {}, 'adaptation_parameters': {'task_nodes': 1, 'task_cores_per_node': 4, 'task_memory_per_node': 0, 'request_task_cores': 4, 'if_initiator_baseline': True}}
- job_controller.py: 更新job 参数信息,并进行参数校验
- job_controller.py: 调用job_utils.save_job_conf() 生成job_dsl, job_runtime_conf,
job_runtime_conf_on_party,train_runtime_conf,pipeline_dsl 各项的保存目录,
并将相关参数以json格式落盘。这里和24 的操作一致,会入两次盘。 - job_controller.py: 调用initialize_task, 初始化task。
- job_controller.py: 基于common_job_parameters, dsl_parser ,调用TaskController.create_task()生成各个role & party_id 上的task
- task_controller.py: 设置task_info 的各项信息
- task_controller.py: 调用JobSaver.create_task()
job_saver.py: 调用create_job_family_entity将相关task信息入DB
这里在fate_flow/peewee.log 中打出了日志1
[DEBUG] [2021-07-26 08:20:31,079] [1:140259111192320] - peewee.py[line:2863]: ('INSERT INTO `t_task` (`f_create_time`, `f_create_date`, `f_update_time`, `f_update_date`, `f_job_id`, `f_component_name`, `f_task_id`, `f_task_version`, `f_initiator_role`, `f_initiator_party_id`, `f_federated_mode`, `f_federated_status_collect_type`, `f_status`, `f_role`, `f_party_id`, `f_run_on_this_party`, `f_party_status`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)', [1627287631077, datetime.datetime(2021, 7, 26, 8, 20, 31), 1627287631078, datetime.datetime(2021, 7, 26, 8, 20, 31), '202107260820309976351', 'upload_0', '202107260820309976351_upload_0', 0, 'local', '0', 'MULTIPLE', 'PULL', 'waiting', 'local', '0', True, 'waiting'])
job_controller.py: 调用initialize_job_tracker,初始化tracker。
- job_controller.py: 初始化 tracker,并调用tracker.log_job_view
- job_tracker.py: 调用log_job_view 将相关信息写db,并在peewee.log 打日志
调用源码位于 python/fate_flow/operation/job_tracker.py 312行这里在fate_flow/peewee.log 中打出了日志如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15@DB.connection_context()
def bulk_insert_into_db(self, model, data_source):
try:
try:
DB.create_tables([model])
except Exception as e:
schedule_logger(self.job_id).exception(e)
batch_size = 50 if RuntimeConfig.USE_LOCAL_DATABASE else 1000
for i in range(0, len(data_source), batch_size):
with DB.atomic():
model.insert_many(data_source[i:i+batch_size]).execute()
return len(data_source)
except Exception as e:
schedule_logger(self.job_id).exception(e)
return 0
1 | [DEBUG] [2021-07-26 08:20:31,122] [1:140259111192320] - peewee.py[line:2863]: ('SELECT table_name FROM information_schema.tables WHERE table_schema = DATABASE() AND table_type != %s ORDER BY table_name', ('VIEW',)) |
- job_controller.py: 调用JobSaver.create_job()
job_saver.py: 调用create_job_family_entity将相关job信息 写db fate_flow/peewee.log
1
[DEBUG] [2021-07-26 08:20:31,385] [1:140259111192320] - peewee.py[line:2863]: ('INSERT INTO `t_job` (`f_create_time`, `f_create_date`, `f_update_time`, `f_update_date`, `f_job_id`, `f_name`, `f_description`, `f_tag`, `f_dsl`, `f_runtime_conf`, `f_runtime_conf_on_party`, `f_train_runtime_conf`, `f_roles`, `f_work_mode`, `f_initiator_role`, `f_initiator_party_id`, `f_status`, `f_role`, `f_party_id`, `f_is_initiator`, `f_progress`, `f_ready_signal`, `f_cancel_signal`, `f_rerun_signal`, `f_end_scheduling_updates`, `f_cores`, `f_memory`, `f_remaining_cores`, `f_remaining_memory`, `f_resource_in_use`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)', [1627287631382, datetime.datetime(2021, 7, 26, 8, 20, 31), 1627287631382, datetime.datetime(2021, 7, 26, 8, 20, 31), '202107260820309976351', '', '', '', '{"components": {"upload_0": {"module": "Upload"}}}', '{"initiator": {"role": "local", "party_id": 0}, "job_parameters": {"common": {"job_type": "train", "work_mode": 1, "backend": 0, "computing_engine": "EGGROLL", "federation_engine": "EGGROLL", "storage_engine": "EGGROLL", "engines_address": {}, "federated_mode": "MULTIPLE", "task_parallelism": 1, "computing_partitions": 4, "federated_status_collect_type": "PULL", "model_id": "local-0#model", "model_version": "202107260820309976351", "eggroll_run": {}, "spark_run": {}, "rabbitmq_run": {}, "adaptation_parameters": {"task_nodes": 1, "task_cores_per_node": 4, "task_memory_per_node": 0, "request_task_cores": 4, "if_initiator_baseline": true}}}, "role": {"local": [0]}, "component_parameters": {"role": {"local": {"0": {"upload_0": {"name": "hetero_guest", "head": 1, "file": "/data/projects/fate/jobs/202107260820309976351/fate_upload_tmp/breast_hetero_guest.csv", "partition": 1, "namespace": "cl", "destroy": false}}}}}, "dsl_version": 2}', '{"initiator": {"role": "local", "party_id": 0}, "job_parameters": {"job_type": "train", "work_mode": 1, "backend": 0, "computing_engine": "EGGROLL", "federation_engine": "EGGROLL", "storage_engine": "EGGROLL", "engines_address": {"computing": {"cores_per_node": 20, "nodes": 1}, "federation": {"host": "rollsite", "port": 9370}, "storage": {"cores_per_node": 20, "nodes": 1}}, "federated_mode": "MULTIPLE", "task_parallelism": 1, "computing_partitions": 4, "federated_status_collect_type": "PULL", "model_id": "local-0#model", "model_version": "202107260820309976351", "eggroll_run": {"eggroll.session.processors.per.node": 4}, "spark_run": {}, "rabbitmq_run": {}, "adaptation_parameters": {"task_nodes": 1, "task_cores_per_node": 4, "task_memory_per_node": 0, "request_task_cores": 4, "if_initiator_baseline": false}}, "role": {"local": [0]}, "component_parameters": {"role": {"local": {"0": {"upload_0": {"name": "hetero_guest", "head": 1, "file": "/data/projects/fate/jobs/202107260820309976351/fate_upload_tmp/breast_hetero_guest.csv", "partition": 1, "namespace": "cl", "destroy": false}}}}}, "dsl_version": 2}', '{}', '{"local": [0]}', 1, 'local', '0', 'waiting', 'local', '0', True, 0, False, False, False, 0, 0, 0, 0, 0, False])
party_app.py: 对应48,若以上步骤都未 raise 异常,则调用get_json_result, 生成返回信息 success 给。 否则抛出异常
- party_app.py: 返回信息给server端,对应46
- fate_flow_server.py: 返回response 给api_utils.py,对应45
- api_utils.py: 返回response 给 federated_scheduler.py,对应44
- federated_scheduler.py: 根据response生成federated_response
- federated_scheduler.py: 返回federated_response 给dag_scheduler.py,对应42
- dag_scheduler.py: 返回federated_response 给data_access_app.py,对应13
- data_access_app.py: 返回federated_response 给fate_flow_server.py,对应3
- fate_flow_server.py: 返回federated_response 给 fate_flow_client.py 对应2
- fate_flow_client.py: 调用prettify 在console 打印日志
至此,任务提交成功