综述
- 代码:python/fate_flow/fate_flow_server.py
- web框架:Flask
流程为:
- 执行 python fate_flow_server.py ,这部分会在容器中打出相应日志。
fate_flow_server 执行启动过程。这里可以看下logs目录
1
2
3
4
5
6(app-root) bash-4.2# pwd
/data/projects/fate/logs
(app-root) bash-4.2# ls
fate_flow
(app-root) bash-4.2# ls fate_flow/
DEBUG.log fate_flow_detect.log fate_flow_schedule.log fate_flow_stat.log INFO.log peewee.log可以看到,由于没有提交任何任务,当前只有一个fate_flow的目录,这里记录的是fate_flow_server启动的日志。具体而言
- peewee.log:fate中操作db,使用了peewee,这里记录所有通过peewee操作数据库的日志
- fate_flow_detect.log:探测器日志
- fate_flow_schedule.log:调度器日志
- fate_flow_stat.log:除以上3部分外的其余状态日志
- DEBUG.log、INFO.log、WARNING.log、ERROR.log:各级别日志,会将以上各部分(除了fate_flow_detect.log,这个后续单独说明逻辑)中对应级别的日志收集。
因fate_flow_server 启动的日志,均输出在fate_flow 目录中,故本文所述的日志,均为fate_flow目录中的对应日志。
执行 fate_flow_server.py
由于是KubeFATE 部署,直接查看容器日志即可。1
2
3
4
5
6
7
8
9
10+ mkdir -p /data/projects/fate/conf/
+ cp /data/projects/fate/conf1/transfer_conf.yaml /data/projects/fate/conf/transfer_conf.yaml
+ cp /data/projects/fate/conf1/service_conf.yaml /data/projects/fate/conf/service_conf.yaml
+ cp /data/projects/fate/conf1/pipeline_conf.yaml /data/projects/fate/conf/pipeline_conf.yaml
+ sed -i 's/host: fateflow/host: 10.200.96.237/g' /data/projects/fate/conf/service_conf.yaml
+ sed -i 's/ip: fateflow/ip: 10.200.96.237/g' /data/projects/fate/conf/pipeline_conf.yaml
+ cp -r /data/projects/fate/examples /data/projects/fate/examples-shared-for-client
+ sleep 5
+ python ./fate_flow/fate_flow_server.py
* Running on http://10.200.96.237:9380/ (Press CTRL+C to quit)
从上述命令可以看出,涉及操作是创建目录->复制配置文件->启动 fate_flow_server.py。
fate_flow_server 启动细节
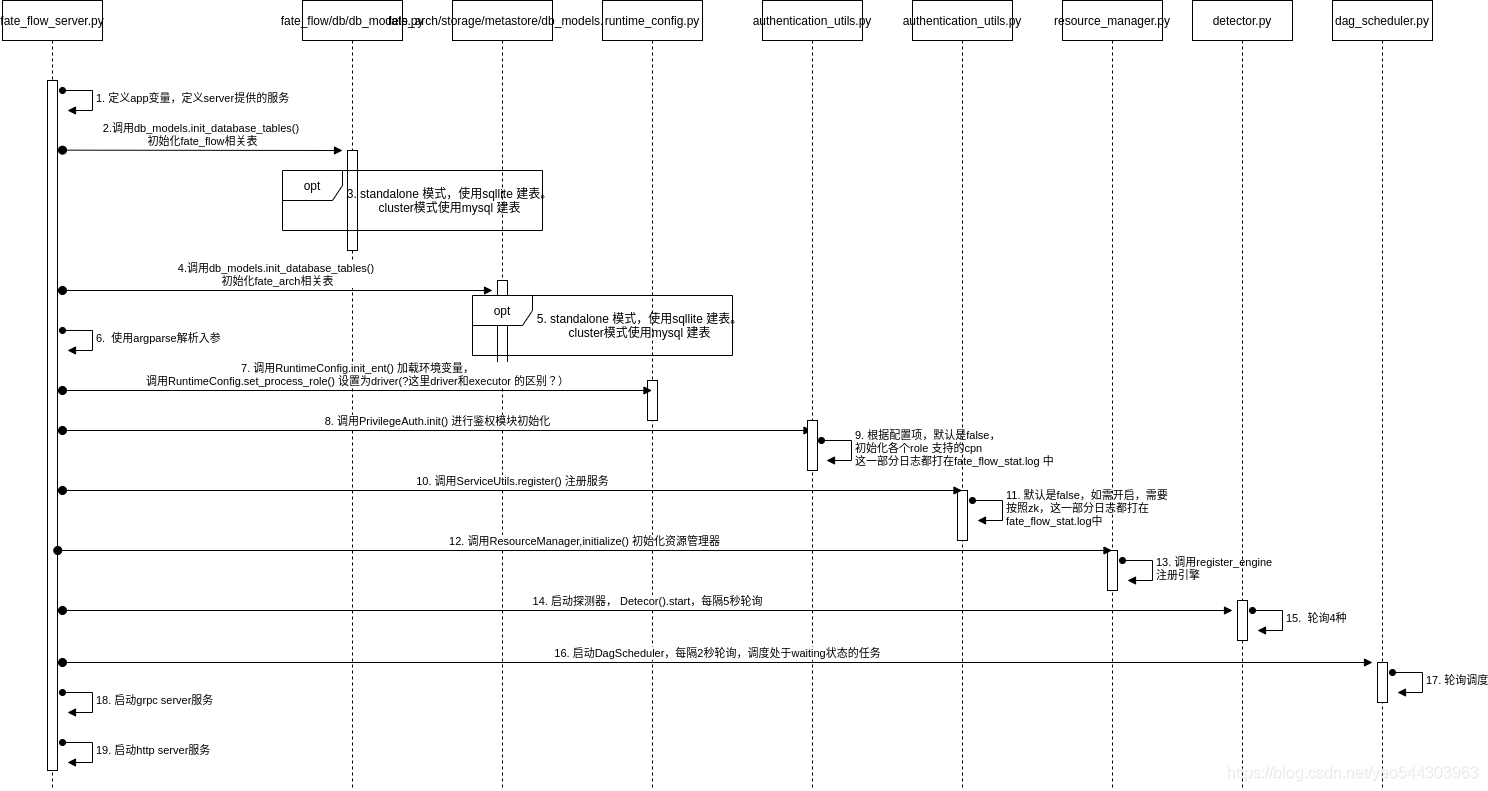
fate_flow_server.py:定义app变量,定义server能提供的服务,这一部分源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17app = DispatcherMiddleware(
manager,
{
'/{}/data'.format(API_VERSION): data_access_app_manager,
'/{}/model'.format(API_VERSION): model_app_manager,
'/{}/job'.format(API_VERSION): job_app_manager,
'/{}/table'.format(API_VERSION): table_app_manager,
'/{}/tracking'.format(API_VERSION): tracking_app_manager,
'/{}/pipeline'.format(API_VERSION): pipeline_app_manager,
'/{}/permission'.format(API_VERSION): permission_app_manager,
'/{}/version'.format(API_VERSION): version_app_manager,
'/{}/party'.format(API_VERSION): party_app_manager,
'/{}/initiator'.format(API_VERSION): initiator_app_manager,
'/{}/tracker'.format(API_VERSION): tracker_app_manager,
'/{}/forward'.format(API_VERSION): proxy_app_manager
}
)不同的manager对应不同模块的功能。详细说明参照REF1,
fate_flow_server.py:调用db_models.init_database_tables()具体执行在 3 中。这里代码里是init_flow_db(),实际是db_models.init_database_tables()的别名。用来和init_arch_db()区分。
fate_flow/db/db_models.py: 初始化fate_flow相关表。注意,在类初始化时,这里会进行一次判断,cluster模式使用mysql,standalone 模式使用sqlite。这一部分日志会输出到fate_flow_stat.log 中:
1
[INFO] [2021-07-26 07:14:02,439] [1:140691673888576] - db_models.py[line:60]: init mysql database on cluster mode successfully
这里涉及t_job、t_task、t_tracking_metric、t_tracking_output_data_info、t_machine_learning_model_info、t_model_tag、t_tags、t_component_summary、t_model_operation_log、t_engine_registry 等10张表。会执行建表和建索引的相关操作。各表具体字段可以查看源码。这部分日志会在peewee.log 中打出。
1
('CREATE TABLE IF NOT EXISTS `componentsummary` (`f_id` BIGINT AUTO_INCREMENT NOT NULL PRIMARY KEY, `f_create_time` BIGINT, `f_create_date` DATETIME, `f_update_time` BIGINT, `f_update_date` DATETIME, `f_job_id` VARCHAR(25) NOT NULL, `f_role` VARCHAR(25) NOT NULL, `f_party_id` VARCHAR(10) NOT NULL, `f_component_name` TEXT NOT NULL, `f_task_id` VARCHAR(50), `f_task_version` VARCHAR(50), `f_summary` LONGTEXT NOT NULL)', [])
注:本地debug时,默认为standalone模式,会在目录生成一个fate_flow_sqlite.db数据库文件
fate_flow_server.py: 调用db_models.init_database_tables() 具体执行在5。
- fate_arch/storage/metastore/db_models.py:初始化fate_arch相关表,和3类似,也会根据部署模式选择不同的数据库。
诶,然后这里没打日志。。。
这里涉及t_storage_table_meta、t_session_record 两张表。也会执行建表和建索引的相关操作。各表具体字段可以查看源码。这部分日志会在peewee.log 中紧接着3打出。 - fate_flow_server.py: 使用argparse解析入参
- fate_flow_server.py:调用RuntimeConfig.init_ent() 加载环境变量,调用RuntimeConfig.set_process_role() 设置为driver(?这里driver和executor 的区别?)
- fate_flow_server.py:调用PrivilegeAuth.init() 进行鉴权模块初始化。
- authentication_utils.py:根据配置项(默认是否)决定是否初始化各个role支持的component,这一部分日志会输出在fate_flow_stat.log中。
- fate_flow_server.py:调用ServiceUtils.register() 注册服务
- authentication_utils.py:根据配置项(默认是否),决定是否注册。如需注册,需要安装zookeeper,这一部分日志会输出在fate_flow_stat.log中。
- fate_flow_server.py:调用ResourceManager.initialize() 初始化资源管理器
- resource_manager.py:调用register_engine 初始化各项信息。
这里会根据配置文件python/fate_flow/settings.py 中的如下内容遍历不同的EngineType的engine_name,即COMPUTING、STORAGE、FEDERATION三个部分,创建相关记录。再将如上EngineType中各个engine_name替换为standalone,再遍历一次。1
2
3
4
5
6
7
8
9
10
11
12
13# Storage engine is used for component output data
SUPPORT_BACKENDS_ENTRANCE = {
"fate_on_eggroll": {
EngineType.COMPUTING: (ComputingEngine.EGGROLL, "clustermanager"),
EngineType.STORAGE: (StorageEngine.EGGROLL, "clustermanager"),
EngineType.FEDERATION: (FederationEngine.EGGROLL, "rollsite"),
},
"fate_on_spark": {
EngineType.COMPUTING: (ComputingEngine.SPARK, "spark"),
EngineType.STORAGE: (StorageEngine.HDFS, "hdfs"),
EngineType.FEDERATION: (FederationEngine.RABBITMQ, "rabbitmq"),
},
}
创建相关记录流程为先查询f_engine_entrance表中,是有有该f_engine_type和f_engine_name的值,如没有,执行insert 如有,则update 相关信息。故而针对如上配置的流程为:- 依此遍历fate_on_eggroll,fate_on_spark中 clustermanager,clustermanager,rollsite。因select 之后的结果都为空,故相关操作都是create信息,在peewee.log 中的日志为INSERT
- fate_on_eggroll中,将engine_name替换为standalone后,再一次遍历。因select 之后的结果都为空,故相关操作都是create信息,在peewee.log 中的日志为INSERT。
- fate_on_spark中,将engine_name替换为standalone后,再一次遍历。因上一步已经create相关记录,皆为update操作,在peewee.log 中的日志为UPDATE。
sql执行情况样例见 peewee.log1
2
3
4[DEBUG] [2021-07-26 07:14:06,066] [1:140691673888576] - peewee.py[line:2863]: ('SELECT `t1`.`f_create_time`, `t1`.`f_create_date`, `t1`.`f_update_time`, `t1`.`f_update_date`, `t1`.`f_engine_type`, `t1`.`f_engine_name`, `t1`.`f_engine_entrance`, `t1`.`f_engine_config`, `t1`.`f_cores`, `t1`.`f_memory`, `t1`.`f_remaining_cores`, `t1`.`f_remaining_memory`, `t1`.`f_nodes` FROM `t_engine_registry` AS `t1` WHERE ((`t1`.`f_engine_type` = %s) AND (`t1`.`f_engine_name` = %s))', ['computing', 'EGGROLL'])
[DEBUG] [2021-07-26 07:14:06,072] [1:140691673888576] - peewee.py[line:2863]: ('INSERT INTO `t_engine_registry` (`f_create_time`, `f_create_date`, `f_update_time`, `f_update_date`, `f_engine_type`, `f_engine_name`, `f_engine_entrance`, `f_engine_config`, `f_cores`, `f_memory`, `f_remaining_cores`, `f_remaining_memory`, `f_nodes`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)', [1627283646068, datetime.datetime(2021, 7, 26, 7, 14, 6), 1627283646068, datetime.datetime(2021, 7, 26, 7, 14, 6), 'computing', 'EGGROLL', 'clustermanager', '{"cores_per_node": 20, "nodes": 1}', 20, 0, 20, 0, 1])
[DEBUG] [2021-07-26 07:14:06,242] [1:140691673888576] - peewee.py[line:2863]: ('UPDATE `t_engine_registry` SET `f_engine_config` = %s, `f_cores` = %s, `f_memory` = %s, `f_remaining_cores` = (`t_engine_registry`.`f_remaining_cores` + %s), `f_remaining_memory` = (`t_engine_registry`.`f_remaining_memory` + %s), `f_nodes` = %s WHERE ((`t_engine_registry`.`f_engine_type` = %s) AND (`t_engine_registry`.`f_engine_name` = %s))', ['{"nodes": 1, "cores_per_node": 20}', 20, 0, 0, 0, 1, 'storage', 'STANDALONE'])
fate_flow具体的日志,打在fate_flow_stat.log 中,如下:1
2
3
4
5
6
7
8
9
10
11
12[INFO] [2021-07-26 07:14:06,077] [1:140691673888576] - resource_manager.py[line:94]: create computing engine EGGROLL clustermanager registration information
[INFO] [2021-07-26 07:14:06,097] [1:140691673888576] - resource_manager.py[line:94]: create storage engine EGGROLL clustermanager registration information
[INFO] [2021-07-26 07:14:06,117] [1:140691673888576] - resource_manager.py[line:94]: create federation engine EGGROLL rollsite registration information
[INFO] [2021-07-26 07:14:06,139] [1:140691673888576] - resource_manager.py[line:94]: create computing engine SPARK spark registration information
[INFO] [2021-07-26 07:14:06,175] [1:140691673888576] - resource_manager.py[line:94]: create storage engine HDFS hdfs registration information
[INFO] [2021-07-26 07:14:06,199] [1:140691673888576] - resource_manager.py[line:94]: create federation engine RABBITMQ rabbitmq registration information
[INFO] [2021-07-26 07:14:06,207] [1:140691673888576] - resource_manager.py[line:94]: create computing engine STANDALONE fateflow registration information
[INFO] [2021-07-26 07:14:06,216] [1:140691673888576] - resource_manager.py[line:94]: create storage engine STANDALONE fateflow registration information
[INFO] [2021-07-26 07:14:06,227] [1:140691673888576] - resource_manager.py[line:94]: create federation engine STANDALONE fateflow registration information
[INFO] [2021-07-26 07:14:06,236] [1:140691673888576] - resource_manager.py[line:76]: update computing engine STANDALONE fateflow registration information takes no effect
[INFO] [2021-07-26 07:14:06,243] [1:140691673888576] - resource_manager.py[line:76]: update storage engine STANDALONE fateflow registration information takes no effect
[INFO] [2021-07-26 07:14:06,253] [1:140691673888576] - resource_manager.py[line:76]: update federation engine STANDALONE fateflow registration information takes no effect
- fate_flow_server.py:启动探测器, Detecor().start,每隔5秒轮询
- detect.py: 一次探测如下四个类型的任务running_task,running_job,resource_record,expired_session,探测到之后,执行相关操作。日志包括两部分,查询DB的日志记录在peewee.log,fate_flow的日志记录在fate_flow/fate_flow_detect.log 中
- running_task:查询db获取所有处于running的TASK的信息->遍历每个TASK的pid,查看是否存在(通过kill(pid,0)检查)。如不存在(不在运行),则存入stop_job_ids-> 遍历stop_job_ids,发起stop请求(此处仍为异步)->打印出running状态的task数量。
- running_job:查询db获取所有处于running的JOB的信息->遍历每个JOB判断是否超时(默认超时限制为3天)-> 对超时的job发起stop请求。
- resource_record:回收资源,查询DB,获取所有资源处于使用中,且任务状态已经结束,并且申请资源时间超过600s的任务,依次遍历任务回收资源。
- expired_session:查询过期(超过5小时)session ,依次遍历并终止
注意,这里打日志,是调用log.py 中 detect_log() 方法,而不是 settings.py 中的LoggerFactory.getLogger(“fate_flow_detect”)1
2
3
4
5
6
7[INFO] [2021-07-26 07:14:11,255] [1:140691103205120] - detector.py[line:38]: start to detect running task..
[INFO] [2021-07-26 07:14:11,264] [1:140691103205120] - detector.py[line:70]: finish detect 0 running task
[INFO] [2021-07-26 07:14:11,264] [1:140691103205120] - detector.py[line:74]: start detect running job
[INFO] [2021-07-26 07:14:11,272] [1:140691103205120] - detector.py[line:88]: finish detect running job
[INFO] [2021-07-26 07:14:11,273] [1:140691103205120] - detector.py[line:93]: start detect resource recycle
[INFO] [2021-07-26 07:14:11,280] [1:140691103205120] - detector.py[line:116]: finish detect resource recycle
[INFO] [2021-07-26 07:14:11,280] [1:140691103205120] - detector.py[line:120]: start detect expired session
- fate_flow_server.py:启动DagScheduler,每隔2秒轮询,调度处于waiting状态的任务
- dag_scheduler.py:调度job,依次调度如下五部分
- 调度处于waiting 状态的job:schedule_waiting_jobs(job=job),调用start_job 启动任务 ,调度的日志输出在fate_flow/fate_flow_scheduler.log 中,start_job 中,再调用FederatedScheduler.start_job(job=job)的日志,就输出到jobid/fate_flow_scheduler.log 中了。
这里每次只能调度一个处于waiting 状态的任务,通过order_by=”create_time” 和 job = jobs[0] 实现 - 调度处于running 状态的job:,不同于waiting,因为是异步提交,考虑到资源问题,每次只调度一个,running状态的调度,主要检查状态等,故从DB中获取到所有running状态的任务后,都会依次遍历,调用schedule_running_job(job=job),是判断任务是否被取消,任务状态为结束时,保存模型。并调用FederatedScheduler.sync_job_status(job=job)同步任务状态。
- 调度ready状态的job:schedule_ready_job(job=job)
- 调度rerun任务的job:schedule_rerun_job(job=job)
- 更新已经为endstatus的job的status:end_scheduling_updates(job_id=job.f_job_id)
1 | [INFO] [2021-07-26 07:14:08,324] [1:140259369826048] - dag_scheduler.py[line:134]: start schedule waiting jobs |
每次查询各状态的任务时,都会操作db,对应的peewee.log 日志类似1
[DEBUG] [2021-07-26 07:14:08,260] [1:140691094812416] - peewee.py[line:2863]: ('SELECT `t1`.`f_create_time`, `t1`.`f_create_date`, `t1`.`f_update_time`, `t1`.`f_update_date`, `t1`.`f_user_id`, `t1`.`f_job_id`, `t1`.`f_name`, `t1`.`f_description`, `t1`.`f_tag`, `t1`.`f_dsl`, `t1`.`f_runtime_conf`, `t1`.`f_runtime_conf_on_party`, `t1`.`f_train_runtime_conf`, `t1`.`f_roles`, `t1`.`f_work_mode`, `t1`.`f_initiator_role`, `t1`.`f_initiator_party_id`, `t1`.`f_status`, `t1`.`f_status_code`, `t1`.`f_role`, `t1`.`f_party_id`, `t1`.`f_is_initiator`, `t1`.`f_progress`, `t1`.`f_ready_signal`, `t1`.`f_ready_time`, `t1`.`f_cancel_signal`, `t1`.`f_cancel_time`, `t1`.`f_rerun_signal`, `t1`.`f_end_scheduling_updates`, `t1`.`f_engine_name`, `t1`.`f_engine_type`, `t1`.`f_cores`, `t1`.`f_memory`, `t1`.`f_remaining_cores`, `t1`.`f_remaining_memory`, `t1`.`f_resource_in_use`, `t1`.`f_apply_resource_time`, `t1`.`f_return_resource_time`, `t1`.`f_start_time`, `t1`.`f_start_date`, `t1`.`f_end_time`, `t1`.`f_end_date`, `t1`.`f_elapsed` FROM `t_job` AS `t1` WHERE ((`t1`.`f_is_initiator` = %s) AND (`t1`.`f_status` = %s)) ORDER BY `t1`.`f_create_time` ASC', [True, 'waiting'])
- fate_flow_server.py:启动grpc server服务,用于不同的rollsite 通信
1
2
3[INFO] [2021-07-26 07:14:06,255] [1:140691673888576] - fate_flow_server.py[line:107]: start grpc server thread pool by 40 max workers
[INFO] [2021-07-26 07:14:06,268] [1:140691673888576] - fate_flow_server.py[line:115]: FATE Flow grpc server start successfully - fate_flow_server.py:启动http server服务,用于处理本地fate_flow_client 和 fate_flow_server 之间的通信。
1
[INFO] [2021-07-26 07:14:06,269] [1:140691673888576] - fate_flow_server.py[line:118]: FATE Flow http server start...