原文:prob140/textbook/notebooks/ch_11
译者:喵十八
自豪地采用谷歌翻译
本章所需python包
1 | # HIDDEN |
1 | # HIDDEN |
1 | # HIDDEN |
1 | # HIDDEN |
1 | # HIDDEN |
1 | # HIDDEN |
1 | # HIDDEN |
反转马尔科夫链
股票市场,变异病毒和计算机搜索引擎有什么共同之处?他们都使用马尔可夫链模型进行了分析。了解马尔可夫链的长期行为有助于我们理解许多不同的随机现象。
在数据科学中,马尔可夫链也用于完全不同的目的。马尔科夫链帮助数据科学家从对于标准采样方法来说太复杂的分布中抽取随机样本。马尔可夫链也可用于分布非常复杂或使用标准方法难以估计的未知量的近似值预估。这可以通过创建马尔可夫链来实现,该马尔可夫链具有作为其稳态分布的原型分布,然后长时间运行链直到它接近稳态。该方法称为马尔科夫链-蒙特卡洛法(Markov Chain Monte Carlo),缩写为MCMC。令人惊讶的是,它涉及了解马尔可夫链反向运行时会发生什么,也就是说当它们被反转时会发生什么。
要理解和实现MCMC算法,您必须研究马尔可夫链的可逆性并进行计算。在本章和随附的实验中,我们将简要介绍这一领域。
详细的平衡
我们一直在研究的马尔可夫链具有稳态分布,其中包含有关链的行为的大量信息。链的稳态分布是平衡方程的解。对于某些链,很容易得到平衡方程的解。但对于其他链条,求解过程可能很复杂或乏味。让我们看看我们是否能找到一种简单的方法来求解平衡方程。
回想一下我们早先关于方程中平衡态的描述。想象一下链的大量独立复制。例如,假设根据链的转移概率,大量粒子在状态间转移,所有粒子在时刻1, 2, 3, $\ldots$的转移都是相对独立的。
假设链处于稳态。正如我们之前所说,设$\pi(k)$为任意时刻离开状态$k$的粒子,那么平衡方程为
当离开状态$j$和进入它的粒子相同时,称链为平衡的。
请注意,左侧只是离开$j$的粒子的比例; 没有关于粒子去向的信息。
现在假设有详细的平衡,由下式给出
这些被称为详细平衡方程。表示对于每一对状态$i$和$j$,离开状态 $i$进入状态$j$的粒子数量和离开状态$j$进入状态$i$的粒子数量一致。在状态$i = j$的情况下,方程无意义,因此被排除在外。
结果证明这是一个比平衡方程更强的条件。
详细平衡意味着平衡
假设存在概率分布 $\pi$ 是详细平衡方程的解,那么$\pi$必然也是平衡方程的解。
我们从中学到的是,如果我们能够求解详细平衡方程,那么我们也能求解平衡方程。
这有两个原因:
- 详细的平衡方程很简单。
- 详细平衡方程的数量很多,如果有$s$个状态,那么有$\binom{s}{2}$ 个详细平衡方程,包含$s$个未知变量。这为我们提供了许多尝试解决它们的方法。
当然,所有这些$\binom{s}{2}$方程不是必须保持一致的,在这种情况下,这些平衡方程无解。在这种情况下,我们只能直接求解平衡方程。这里有一个例子表明,如果详细的平衡方程确实有解,我们就可以轻松地得到链的稳态分布。
爱伦菲斯特链
我们需要回到这个例子,因为它可以通过一些操作来求解平衡方程。我们将展示对于这个链和其他类似的链中,如何简便的求解详细的平衡方程,这为我们提供了一个快速求的稳态分布的途径。
状态空间是整数0到$N$。回想一下转移是如何进行的:在每一步,链条向前转移1个状态,保持不变,或者向后转移1个状态。这些链称为生死链,用于模拟许多随机模型,如赌徒的命运或人口规模。在我们的例子中,模拟了容器中气体粒子的数量。
对于这样的链,1-阶转移矩阵中,大多数转移概率是0,因为在一个步骤中链只能移动到两个相邻状态。所以大多数详细的平衡方程都是正确的。对于那些1-阶转移概率为正的两个状态$i$和$j$,两者之间的间隔必为1。(注意,详细平衡方程指定$i \ne j$)。在那种情况下,由于链不可约,$P(i, j)$和$P(j, i)$都为正。
这允许我们从最低状态开始向上移动来求解详细平衡方程。记住转移规则:
- 在每个步骤中,从$N$中随机选取一个粒子,随意放入两个容器中的一个; 链计算容器1中的粒子数。
详细的平衡方程式可以顺序求解:
等,从而对于$1 \le k \le N$,有
通过比,归纳比求解平衡方程更容易。各项总和为
由二项式定理。所以$\pi(0) = 2^{-N}$并且稳态分布为二项分布$(N, 1/2)$.
在这一点上,值得记住的是对于数值 $N$,你可以使用steady_state来找到稳态分布。依靠Python来为你做所有的工作。这有一些明显的优点,但也有一些缺点:
- 当$N$非常大时,Python无法处理计算。
- 你会看到分布是二项分布,但不知道是怎么得来的。
这就是为什么即使在强大的个人计算机时代,找到使用数学解决问题的好方法仍然很重要。
环形粘性随机漫步
假设一个链在圆上顺时针顺序排列状态0,1,2,3,4。假设在每个步骤中保持在原位的概率为$s$,移动到逆时针邻居的概率为$p$,移动到顺时针邻居的概率为$r$。这里,$s$, $p$和 $r$都为正,且总和为1。
很明显,链的行为在五个状态中是对称的,因此从长远来看,预计在每个状态中花费的时间占比相同。状态上的稳态分布是均匀的。您也可以通过求解平衡方程来校验这一点。
让我们看看上述链是否满足详细的平衡方程。与上面的Ehrenfest链不同,这条链可以“环回”。所以不清楚是否满足详细的平衡方程。
详细的平衡方程是:
到目前为止一切都那么好,现在到了求解真相的关键:
对于这个方程组,有解的前提是$\pi(4)$的两个表达式必须相等,也就是
这只有在$r = p$时才会发生,在这种情况下,详细的平衡方程表示$\pi$ 的所有条目都是相等的,而这是已知的。
总结一下:
- 在所有状态下,链的稳态分布是均匀的。均匀分布满足平衡方程。
- 当$r = p$, 详细的平衡方程有一个正解,即稳态分布。
- 当$r \ne p$详细的平衡方程没有概率分布作为解。
显然,$r = p$ 有特殊的地位。这究竟对这个链的行为意味着什么?这是下一节的主题。目前,这里用于模拟链路径的两组参数:
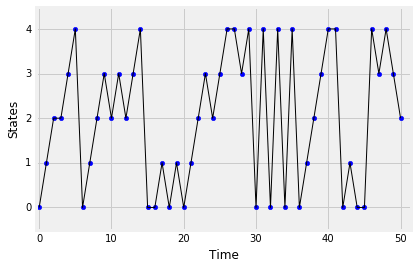
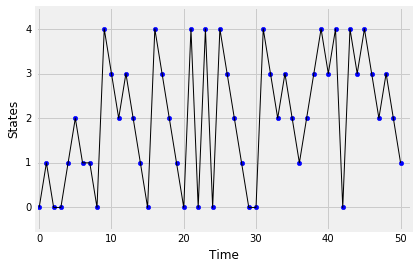
circle_walk_1: $s = 0.1$, $r = 0.6$, $p = 0.3$circle_walk_2: $s = 0.1$, $r = 0.3$, $p = 0.6$
保持原位的机会对于两者都是相同的,但顺时针和逆时针移动的机会已经切换。这是两条链的模拟路径。在图中,“顺时针”显示为向上移动,“逆时针”显示为向下移动。
查看路径(如果您愿意,可以模拟更多路径)并回答以下问题:
- 哪一个有“向上”转移而不是“向下”?
- 如果有人向您展示了这两个流程之一的路径,但没有说明这两个流程中的哪一个,您能否确定是哪一个?
1 | states = np.arange(5) |
1 | circle_walk_1 |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.1 | 0.6 | 0.0 | 0.0 | 0.3 |
| 1 | 0.3 | 0.1 | 0.6 | 0.0 | 0.0 |
| 2 | 0.0 | 0.3 | 0.1 | 0.6 | 0.0 |
| 3 | 0.0 | 0.0 | 0.3 | 0.1 | 0.6 |
| 4 | 0.6 | 0.0 | 0.0 | 0.3 | 0.1 |
1 | circle_walk_1.simulate_path(0, 50, plot_path=True) |
1 | s = 0.1 |
1 | circle_walk_2 |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.1 | 0.3 | 0.0 | 0.0 | 0.6 |
| 1 | 0.6 | 0.1 | 0.3 | 0.0 | 0.0 |
| 2 | 0.0 | 0.6 | 0.1 | 0.3 | 0.0 |
| 3 | 0.0 | 0.0 | 0.6 | 0.1 | 0.3 |
| 4 | 0.3 | 0.0 | 0.0 | 0.6 | 0.1 |
1 | circle_walk_2.simulate_path(0, 50, plot_path=True) |
可逆性
前一部分的随机漫步在环上顺时针顺序排列的状态0,1,2,3,4。在每个步骤中保持在原位的概率为$s$,移动到逆时针邻居的概率为$p$,移动到顺时针邻居的概率为$r$。链的稳态分布为每个状态的概率为0.2。
若$r > p$, 那么链更可能顺时针方向而不是逆时针方向移动。例如,在稳态下,路径$0, 1, 2, 3$的概率为:
所述路径的反转路径 $3, 2, 1, 0$ 的概率为
若 $r > p$,那么原始路径的概率更高。
但如果$r = p$,那么原始路径与反向路径的概率相同; 在稳定状态下,链条可能朝任何一个方向上运行。如果某人在稳定状态下模拟链并向您显示原始路径以及反向路径,您将无法分辨哪个是哪个。
在本节中,我们将定义马尔科夫链以这种方式可逆的意义。
反转过程
设$X_0, X_1, \ldots $是一个定义在有限状态空间下,具有稳态分布$\pi$的不可约马尔可夫链。以这种稳态分布启动该链,也就是说,让$X_0$具有分布$\pi$。然后对于所有的$n \ge 1$,$X_n$的分布也是$\pi$。
修正,令$n > 0$,并考虑反向序列$Y0, Y_1, \ldots, Y_n$,其中$Y_k = X{n-k}$, $k = 0, 1, \ldots, n$。称$X_0, X_1, \ldots, X_n$为正向序列。
反向序列是时间同质马尔可夫链的一个很好实例。为了了解原因,我们将检查马尔科夫性质是否成立。
在我们证明一般事实之前,让我们进行一些探索性的计算。从$n = 1$开始,此时有$Y_0 = X_1$ 和$Y_1 = X_0$。对于状态$i$和$j$。
因为正向序列处于稳定状态。我们已经使用转移矩阵和前向序列的稳态分布找到了反向序列的转移概率。
对于$n = 2$,我们有$Y_0 = X_2$,$Y_1 = X_1$, 和 $Y_2 = X_0$。对于状态$k$,$i$,和$j$
解不依赖于$k$。这与马尔科夫性质保持一致。另外结合我们刚刚证明的两个事实,可以发现,转移概率是时间同质的。
对于更一般的$n$,修正状态$i$和$j$以及 0到$n-1$之间的整数$m$有
这只涉及状态$i$和$j$,而和$i0, i_1, \ldots, i{m-1}$以及$m$无关。因此满足马尔可夫性质,转移概率是时间同质的。反向序列”状态$i$到状态$j$”的1-阶转移概率为
可逆链
当原来的正向马尔科夫链$X_0, X_1, \ldots $中,对于每个$n$,其反向序列$Y_0, Y_1, \ldots Y_n$的1-阶转移概率和原始序列一样的情况,被称作是可逆的。也就是说
如果链可逆,则有
换言之:
如果详细的平衡方程具有正解,则链是可逆的。 这与我们在稳状下根据该链想象粒子的移动情况一致:在每个时刻,对于每一对状态$i$和$j$,粒子从$i$移动到$j$的比例与从$j$移动到$i$的比例完全相同。
在本节开始时,我们查看了一个环上的随机漫步。让我们看看可逆性的定义对于这个链是什么意思。
在上一节中,我们展示了当 $p \ne r$时,详细的平衡方程没有正解。因此,当 $p \ne r$时,链条是不可逆的。这与我们之前的分析一致。
当$p = r$时,我们找到了详细平衡方程的解,因此链是可逆的。这形式化了我们的猜想,即如果$p = r$,那么在稳态下,链条“正向或者反向运行是一样的”。
生死链的可逆性
回想一下,生死链是定义在整数上的马尔可夫链,其每一步的转移限制为增加1,减少1或者保持不变。不难校验具有有限状态空间的不可约的生死链是否可逆。您可以像我们在上一节中对Ehrenfest链所做的那样,通过求解详细的平衡方程来校验。
返回并查看文本和练习中的示例。切换链,反射随机漫步(包括懒惰和非懒惰的),Ehrenfest链和伯努利 - 拉普拉斯链都是不可简约的生死链,因此都是可逆的。
让我们在乍一看似乎不可逆转的生死链的情况下证实这一点。这是马尔可夫链 $X_0, X_1, \ldots $的转移图。
![]()
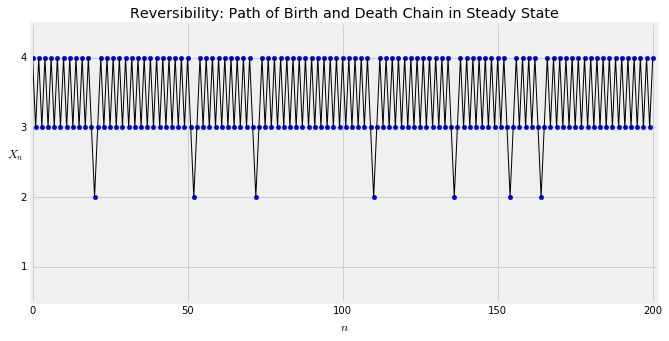
这条链以较高的概率向右移动(即生有孩子),所以看起来好像我们应该知道它是正向还是反向移动。但请记住,时间逆转发生在稳态。在稳态下,链条可能在状态3和4之间穿梭。您可以通过求解详细的平衡方程式来看到这一点。
它也将访问状态2和1,但很少,状态1特别罕见。这些访问将散布3和4中,并且这些路径将无法区分正向和反向移动。
让我们模拟这个过程的路径。首先,我们构造转移矩阵并确认我们$\pi$的计算。
1 | s = np.arange(1, 5) |
1 | pi = bnd.steady_state() |
| Value | Probability |
|---|---|
| 1 | 0.00549451 |
| 2 | 0.0549451 |
| 3 | 0.494505 |
| 4 | 0.445055 |
我们可以使用simulate_path来绘制链的路径。请注意,与我们以前使用此方法不同,我们现在将初始分布作为第一个参数传递,而不是特定状态。第二个参数是步骤数,如前所述。
下图显示了一条长度为200的路径。运行单元格几次,并向前和向后查看每条路径。你不会发现两者之间的系统差异。
1 | plt.figure(figsize=(10,5)) |
密码破解
有趣的是,虽然许多马尔可夫链是可逆的,但到目前为止我们看到的例子并没有解释我们通过反转链条得到的结果。毕竟,如果它看起来像正向一样向前运行,为什么不向前运行呢?为什么要担心可逆性呢?
事实证明,逆转马尔可夫链可以帮助解决其他方法难以处理的一类问题。在本节中,我们将介绍如何出现此类问题的示例。在下一节中,我们将讨论一个解决方案。
假设
在网络安全成为我们生活的一部分之前,人们就已经对加密和解密非常感兴趣了。解码加密信息可能是复杂且计算密集的。逆转马尔可夫链可以帮助我们完成这项任务。
为了了解解决此类问题的方法以及问题的涉及范围,让我们尝试解码使用称为替代代码的简单代码加密的一小段文本。文本以字母表写,您可以将其视为一组字母和标点符号。在替换代码中,字母表中的每个字母简单地被另一个字母替换,使得代码只是字母表的排列。
要解码由替换代码加密的消息,您必须反转使用的排列。换句话说,您必须对编码消息应用置换以恢复原始文本。我们将这个置换称为解码器。
要解码文本消息,我们必须做出一些假设。例如,了解编写消息的语言,以及该语言中常见的字母组合。具体而言,就假设我们尝试解码用英语编写然后加密的消息。如果我们的解码过程以zzxtf和tbgdgaa之类的“单词”结束,我们可能想尝试不同的方式。
所以我们需要关于哪些字母序列是常见的数据。这些数据现在越来越容易收集; 例如由 Peter Norvig, 一个谷歌的研究总监负责的网页
解码信息
让我们看看我们如何使用这种方法来解码消息。为简单起见,假设我们的字母表只包含三个字母a,d和t。现在假设我们得到编码消息atdt。我们相信这是一个英文单词。我们怎么能以一种可以被计算机重复的方式来解码呢?
作为第一步,我们将记下所有3!= 6个字母表中字母的可能排列,并使用每个字母对消息进行解码。该表decoding包含所有结果。Decoder中的每个条目都是一个排列,我们将应用于我们的编码文本atdt。确定我们将在解码过程中对哪些字母置换。
要了解如何执行此操作,请首先将字母“按字母顺序”的排序:’a’,’d’,’t’。现在看一下表格的行。
第一行中的解码器是[‘a’,’d’,’t’]。这个解码器简单地保持字母不变; atdt被解码为atdt。
第二行中的解码器是[‘a’,’t’,’d’]。这使得字母’a’的第一个字母保持不变,但将第二个字母’d’替换为’t’,将第三个字母’t’替换为’d’。
所以atdt被解码为adtd。
您可以以相同的方式阅读表格的其余部分。.
请注意,在每个已解码的消息中,在索引1和3处出现相同字母。这是用于解码atdt中的t的字母。替换代码的一个特征是每个字母原件都用相同的字母进行置换,因而字母原件出现在文本中的位置都会替换为相同的替换字母。解码器必须具有相同的功能。
1 | decoding |
| Decoder | atdt Decoded |
|---|---|
| ['a' 'd' 't'] | ['a' 't' 'd' 't'] |
| ['a' 't' 'd'] | ['a' 'd' 't' 'd'] |
| ['d' 'a' 't'] | ['d' 't' 'a' 't'] |
| ['d' 't' 'a'] | ['d' 'a' 't' 'a'] |
| ['t' 'a' 'd'] | ['t' 'd' 'a' 'd'] |
| ['t' 'd' 'a'] | ['t' 'a' 'd' 'a'] |
我们应该使用哪一个解码器?为了做出这个决定,我们必须了解英语中单词中,字母串转移的频率。我们的目标是根据解码结果中字母串的转移频率选择解码器。
我们用汇总了英语中,一些双字母或两个字母组合频率的数据。这是一个被称为bigrams的转移矩阵,用于对英语中双字母的可用信息进行粗略简化; 我们使用了Peter Norvig的双字母表,并将其限制在我们的三个字母的字母表中。对应于字母’a’的行假定以’a’开头的大约2%的双字母是’aa’,大约22%是’ad’,剩下的76%是’at’。
“aa”组合是罕见的,这是有道理的; 我们不经常使用像aardvark这样的词。甚至2%看起来很大,直到你记得它只是’aa’,’ad’和’at’中’aa’的比例,因为我们限制了字母表。如果你看它在所有 $26\times26$ 中的比例,会低得多。
1 | bigrams |
| a | d | t | |
|---|---|---|---|
| a | 0.018099 | 0.219458 | 0.762443 |
| d | 0.570995 | 0.159772 | 0.269233 |
| t | 0.653477 | 0.049867 | 0.296656 |
现在将真实文本视为具有此转移矩阵的马尔可夫链的路径。一个有趣的历史是,这就是马尔科夫第一次提出马尔科夫过程时所做的事情 - 他分析了亚历山大普希金的韵文小说,Eugene Onegin 中元音和辅音之间的转移。
如果真实的文本是tada,那么我们可以将序列tada视为马尔可夫链的路径。其概率可以由$P(t)P(t, a)P(a, d)P(d, a)$计算。我们将根据这个概率给每个解码器一个分数。较高的分数对应于更好的解码器。
为了分配分数,我们假设所有三个字母都以相同的概率开始路径。对于字母表中的三个字母,这与事实并不相符(每个字母出现的概率并不相同,我们可以忽略这一因素)。这意味着每条路径的概率将以1/3的系数开始,我们所要做的就是对所有概率进行排名。我们将只计算$P(t, a)P(a, d)P(d, a)$,值约为 8%。
根据我们上面decoding的表格,tada是我们通过将解码器[‘t’,’d’,’a’]应用到我们的数据atdt得到的结果。现在,我们可以说这个解码器在给定数据上的得分是8%。稍后我们将介绍更正式的计算和术语。
1 | # score of decoder ['t', 'd', 'a'] |
0.08188682431730866
为了自动化这种计算,我们可以使用prob_of_path方法。请记住,它的第一个参数是初始状态,第二个参数是由序列中剩余状态组成的列表或数组。
1 | bigrams.prob_of_path('t', ['a', 'd', 'a']) |
0.081886816291942444
我们是否应该决定将我们的消息atdt解码为tada?如果我们认为8%的可能性很高,那么答案为是。但,如果其他的解码器具有更高的可能性呢?在那种情况下,当然选择得分高的。
因此,我们需要全部六个“解码器”路径中的概率。
让我们定义一个函数score,它将获取一个列表或一组字符,并使用bigrams转移矩阵返回相应路径的概率。在我们的示例中,这与返回相应解码器的分数相同。
1 | def score(x): |
以下是按分数降序排列的结果。有一个明显的赢家:对应于消息’data’的解码器[‘d’,’t’,’a’]的分数是任何其他解码器的两倍以上。
1 | decoding = decoding.with_column('Score of Decoder', decoding.apply(score, 1)) |
| Decoder | atdt Decoded | Score of Decoder |
|---|---|---|
| ['d' 't' 'a'] | ['d' 'a' 't' 'a'] | 0.284492 |
| ['d' 'a' 't'] | ['d' 't' 'a' 't'] | 0.134142 |
| ['t' 'd' 'a'] | ['t' 'a' 'd' 'a'] | 0.0818868 |
| ['a' 'd' 't'] | ['a' 't' 'd' 't'] | 0.0102363 |
| ['t' 'a' 'd'] | ['t' 'd' 'a' 'd'] | 0.00624874 |
| ['a' 't' 'd'] | ['a' 'd' 't' 'd'] | 0.00294638 |
问题的规模
当字母表较大时,我们在三个字符的字母表上做的工作,将会变得非常可怕。52个小写字母和大写字母,以及空格字符和所有标点,形成一个大约70个字符的字母表。这给了我们70!不同的解码器需要考虑。理论上,我们必须找到这70!个中每一个的可能性和并将他们排序。
这是70!个解码器。我们的计算系统无法处理那么多,其他系统也会遇到同样的问题。
下面计算了70!的值
1 | math.factorial(70) |
11978571669969891796072783721689098736458938142546425857555362864628009582789845319680000000000000000
一个可能的解决方案是从这70!个可能的解码器中随机采样,然后只从采样的排序中进行挑选。但是我们如何从70!中进行采样?根据字母表,均匀随机采样并不是一个好主意,因为那不太可能让我们快速获得理想解决方案。
我们希望的采样程序,能够选择具有高概率的良好解码器。好的解码器生成的文本几乎比所有其他解码器生成的文本具有更高概率。换句话说,给定数据,良好的解码器比其他解码器具有更高的可能性。
您可以使用贝叶斯规则记下这种可能性。让 $S$代表所有可能排列的空间; 如果字母表有 $N$字符,然后$S$有$N!$个元素。对于任何随机挑选的排列$j$,给出数据的解码器的概率是:
对于给定的编码文本,分母是使所有似然性总和为1的归一化常数项。它出现在每个解码器的可能性中。在我们使用三个字母字母表的示例中,我们忽略了它,因为我们可以找出所有六个解码器的分子并且只是比较它们。分子就是我们称之为解码器的分数。
即使字母表很大,对于任何特定的解码器 $j$我们可以通过转移概率顺序相乘计算得到分子,就像我们在我们的例子中所做的那样。但是对于所有可能的解码器,我们无法对全量解码器执行此操作,因此我们无法列出所有可能的分数,我们无法对他们求和。因此,我们不知道可能性的分母,甚至找不到合适的近似值。
我们现在需要的是一种方法,即使我们不知道归一化常数,也可以从概率分布中得出一个近似解。这就是Markov Chain Monte Carlo帮助我们做的事情。
马尔可夫链蒙特卡罗法
马尔可夫链蒙特卡罗(MCMC)的目标是从复杂的高维分布中生成随机样本,这种情况下,我们的信息不完整。例如,我们可能不知道分布的归一化常量,正如我们在上一节的示例中看到的那样。
比如我们想根据分布$\pi$生成样本。我们就假设$\pi$是一个非常巨大有限集上的概率分布。MCMC依赖于较少的采样值。
设$X_0, X_1, \ldots $是一个定义在有限空间上的不可约非周期性马尔科夫链。那么,当$n$变大时,$X_n$的分布趋向于稳态。如果我们可以创建一个稳态分布为$\pi$ 的马尔科夫链${X_n}$ ,那么我们使用对于一个较大值$n$的 $X_n$,来长期运行链条,从而模拟$\pi$(或其近似值)。
构建一个使得最终稳态分布为$\pi$的转移矩阵的最简单的方式是保证详细平衡方程有解。换言之,最简单的方法是尝试创建一个可逆链。
如果链是可逆的,那么详细平衡方程可以改写为:
右侧只涉及我们想要创建的链的转移概率。左侧仅涉及$\pi$中的项的比率。因此,即使我们不知道使$\pi$归一化的常数,也可以得到校验。
Metropolis 算法
究竟是谁第一个提出了相关算法来创建这样的马尔可夫链存在一定争议。黑斯廷斯提出了一般版本。在这里,我们将描述于1953年由Metropolis和共同作者提出的早期版本。
目标是创建一个转移矩阵 $\mathbb{P}$,使得$\pi$和$\mathbb{P}$能一起求解详细平衡方程。
该算法基于任意的对称转移矩阵$Q$,该矩阵会在状态空间上创建一个不可约的非周期性链。例如,如果状态空间是数值,你可以用“无论链条,它选择三个最接近的值(包括自身,每个的概率都是$1/3$)中的一个”开始链。对于一对状态$i$和$j$,转移概率$Q(i, j)$被称为提议概率。
以下是确定新链转移的步骤。
假设连载时刻$n$时为状态$i$,即$X_n = i$。根据提议概率$Q(i, j)$选择一个状态$j$。这个$j$是链可能的目的状态。
定义接受概率如下
如果 $r(i, j) \ge 1$, 则 $X_{n+1} = j$.
如果 $r(i, j) < 1$, 通过抛硬币的方式,随机选择$r(i, j)$。
- 如果硬币正面向上,则 $X_{n+1} = j$.
- 如果硬币反面向上,则 $X_{n+1} = i$.
- 以 $X_{n+1}$为起始值,重复所有步骤。
因此,新链要么移动到$Q$,要么保持原样。我们说它基于$Q$和$r$接受移动到新状态,否则它不动。
因为提案链是不可约的,新的链条也是不可约的。因为它可以保持原位,所以它是非周期性的。因此它具有稳态分布。算法表示这种稳态分布与$\pi$相同,即我们定义的$r(i, j)$。
算法的相关思考
在我们证明算法有效之前,让我们先来看看它在解码器环境中的作用。
首先注意$Q$是对称的,也是不可约的。对称性要求是有意义的,因为每个详细的平衡方程涉及转移$i \to j$和$j \to i$。
修正启动的解码器并将其命名为$i$。现在你必须决定链接下一步的位置,即下一个解码器是什么。由该程序启动的算法,在根据$Q$选择了一个$j$之后会关闭。我们称之为$Q$ 建议移动到$j$。
分布$\pi$包含所有解码器的可能性,决定链是否应移至$j$的根本因素是希望最终得到具有高可能性的解码器,因此需要比较$\pi(i)$和$\pi(j)$。
该算法通过比较接受比率 $r(i, j) = \pi(j)/\pi(i)$ 和 1 之间的大小。
如果$r(i, j) \ge 1$,那么$j$的概率至少和$i$一样大,所以你接受提议并且移动到$j$。
如果$r(i, j) < 1$,那么建议的解码器$j$的可能性比当前的$i$要小,所以暂时先保持在$i$。但这可能会使链条陷入局部最大值。该算法通过抛硬币(随机选择)提供了避免这种情况的机会。如果硬币为反面,即使$j$比当前具有更低的可能性,链条移动到$j$。我们的想法是,从这个新位置开始,可能存在解码器的路径,这些解码器具有最高的可能性。
算法实践
我们现在将表明由Metropolis算法创建的链的详细平衡方程,是如何通过期望$\pi$和转移矩阵$\mathbb{P}$求解的。
选择任意两个状态$i$和$j$
案例 1: $\pi(i) = \pi(j)$
当$r(i, j) = 1$。通过算法和$Q$的对称性,有$P(i, j) = Q(i, j)$和$P(j, i) = Q(j, i) = Q(i, j)$。
因此,$P(i, j) = P(j, i)$,满足详细平衡方程$\pi(i)P(i, j) = \pi(j)P(j, i)$。
案例 2: $\pi(j) < \pi(i)$
当 $r(i, j) < 1$,有
此时 $r(j, i) > 1$,则根据算法有 $P(j, i) = Q(j, i)$。
因此
这与下面是一样的
案例 3: $\pi(j) > \pi(i)$
交换案例 2 中$i$和$j$的角色。
以上就是!一个简单而出色的想法,为困难问题提供解决方案。在实验中,当您实现解码文本的算法时,您将看到它的实际效果。